

S3와 CloudFront로 SPA를 배포하는 구조는 단순해 보입니다. 빌드 결과물을 S3에 올리고, CloudFront가 그 파일들을 서빙하면 됩니다. 하지만 실제 운영 환경에서는 index.html, hashed asset, SPA fallback, CDN cache, 브라우저 cache가 서로 다른 생명주기를 갖습니다.
이 차이를 명확히 나누지 않으면 새 배포 이후 이미 열려 있던 브라우저나 웹뷰에서 ChunkLoadError가 발생하거나, JavaScript 파일 요청에 HTML 문서가 내려오는 것처럼 보이는 혼란스러운 문제가 생길 수 있습니다.
이 글에서는 Vite 기반 SPA를 S3와 CloudFront로 배포하면서 겪은 chunk load error를 계기로, 캐시 정책과 fallback 전략을 어떻게 분리했는지 정리합니다. 사례는 Vite와 React Router에서 출발했지만, 결론은 특정 프레임워크보다 정적 SPA 배포 구조 전반에 가까웠습니다.
이 글에서 다루는 문제
문제는 새 프론트 배포 이후 이미 열려 있던 웹뷰에서 route 이동을 할 때 발생했습니다.
처음 화면 진입은 정상적으로 보였지만, 사용자가 lazy route로 이동하는 순간 React Router의 ErrorBoundary로 빠지는 케이스가 있었습니다. 콘솔에서는 상황에 따라 다음과 같은 에러가 보일 수 있었습니다.
Failed to fetch dynamically imported module
Importing a module script failed
Expected a JavaScript module script but the server responded with a MIME type of "text/html"
ChunkLoadError

처음에는 "CloudFront invalidation을 했는데 왜 사용자는 여전히 예전 파일을 보고 있을까?"라고 생각했습니다. 하지만 문제를 따라가 보니 invalidation, 브라우저 cache, 메모리에 올라간 SPA runtime, S3 release prefix, CloudFront fallback 설정이 각각 다른 층위의 문제였습니다.
이 글에서 정리하려는 핵심은 다음과 같습니다.
index.html과 hashed asset은 서로 다른 cache 정책을 가져야 한다.- CloudFront invalidation은 사용자 브라우저나 웹뷰에 이미 올라간 SPA runtime을 바꾸지 않는다.
- SPA fallback은 route 요청만 처리해야 하고, asset 요청까지 삼키면 안 된다.
- missing asset을
index.html200 응답으로 바꾸면 원인이 MIME type mismatch처럼 보일 수 있다. - 인프라 설정만으로 이미 열린 구버전 SPA의 dynamic import 실패를 완전히 없애기는 어렵다.
- 남는 런타임 문제는 프론트에서 reload-once 방어로 보완해야 한다.
S3와 CloudFront로 SPA를 배포할 때 생기는 고민
먼저 배포 구조를 단순화해보겠습니다.
Browser or WebView
-> CloudFront
-> S3
빌드 결과물은 S3에 업로드하고, CloudFront는 S3를 origin으로 바라봅니다. Vite로 빌드한 SPA의 결과물은 대략 다음과 같은 형태입니다.
dist/
index.html
assets/
js/
index.ABC123.js
ReportPage.DEF456.js
여기서 index.html과 assets/js/*.js는 역할이 다릅니다.
index.html은 현재 배포가 어떤 asset hash를 바라보는지 담고 있습니다. 새 배포가 나가면 이 파일은 빠르게 최신 상태로 바뀌어야 합니다.
반대로 assets/js/index.ABC123.js 같은 hashed asset은 파일명에 내용 기반 hash가 들어갑니다. 내용이 바뀌면 파일명도 바뀌기 때문에 오래 cache해도 비교적 안전합니다.
따라서 기본 전략은 다음처럼 나뉘어야 합니다.
index.html
-> 짧게 cache하거나 매번 재검증
assets/*
-> 길게 cache
-> immutable
문제는 SPA fallback이 이 경계를 흐릴 때 생깁니다.
SPA에서는 /reports, /settings/profile 같은 경로가 실제 S3 객체로 존재하지 않습니다. 이 요청은 모두 index.html로 보내야 React Router가 클라이언트에서 route를 해석할 수 있습니다.
하지만 fallback이 너무 넓게 적용되면 /assets/js/missing.js 같은 정적 파일 요청까지 index.html로 바뀔 수 있습니다. 이 경우 브라우저는 JavaScript module을 기대하고 요청했는데 HTML 문서를 받게 됩니다.
문제의 원인
이번 문제는 하나의 설정만으로 설명하기보다, 여러 조건이 이어진 결과로 보는 것이 정확했습니다.
이미 열린 SPA는 새 배포 후에도 그대로 남아 있다
사용자가 웹뷰에서 SPA를 열어둔 상태라면 이미 index.html과 JavaScript runtime이 메모리에 올라가 있습니다.
구버전 index.html
구버전 main JavaScript
구버전 lazy chunk 목록
이 상태에서 새 배포가 나가도 이미 실행 중인 SPA runtime이 자동으로 최신 runtime으로 바뀌지는 않습니다. 사용자가 페이지를 새로고침하거나 앱이 새 문서를 다시 로드해야 최신 index.html과 최신 asset 목록을 받을 수 있습니다.
Vite code splitting은 배포마다 다른 chunk 파일명을 만든다
Vite는 dynamic import나 lazy route 결과물을 hash가 붙은 chunk로 만듭니다.
예를 들어 어떤 페이지 컴포넌트가 이전 배포에서는 다음 파일이었다고 해보겠습니다.
/assets/js/ReportPage.oldhash.js
새 배포 이후에는 같은 페이지가 다른 hash를 가진 파일이 될 수 있습니다.
/assets/js/ReportPage.newhash.js
구버전 runtime은 여전히 oldhash 파일명을 알고 있습니다. 이미 열린 SPA 안에서 나중에 해당 route로 이동하면 구버전 runtime은 예전 chunk를 요청할 수 있습니다.
CloudFront OriginPath가 최신 release prefix를 바라본다
운영 구조에 따라 S3에 배포마다 release prefix를 만들고, CloudFront의 OriginPath를 최신 prefix로 변경하는 방식을 사용할 수 있습니다.
old: /service:dev-aaaaaa
new: /service:dev-bbbbbb
viewer가 보는 URL에는 release prefix가 없습니다.
/assets/js/ReportPage.oldhash.js
하지만 CloudFront가 origin으로 요청을 보낼 때는 현재 OriginPath가 붙습니다.
s3://bucket/service:dev-bbbbbb/assets/js/ReportPage.oldhash.js
구버전 runtime이 요청한 old chunk가 최신 release prefix 아래에 없다면 S3 또는 CloudFront는 403이나 404를 반환합니다.
Custom Error Response가 missing asset을 HTML 200으로 바꿨다
기존에는 SPA deep link 처리를 위해 CloudFront Custom Error Response를 사용하고 있었습니다.
403 -> /index.html
Response code 200
이 설정은 사용자가 /reports 같은 SPA route로 직접 접근했을 때는 편리합니다. 실제 S3 객체가 없어 403이 발생해도 index.html을 내려주면 SPA가 route를 처리할 수 있기 때문입니다.
하지만 같은 설정이 asset 요청에도 적용되면 문제가 됩니다.
즉 Custom Error Response가 old chunk 요청 실패의 최초 원인은 아니었습니다. 최초 원인은 이미 열린 구버전 runtime이 현재 OriginPath 아래에 없는 old chunk를 요청한 것입니다.
다만 Custom Error Response는 이 실패를 실제 403/404로 보여주지 않고 index.html 200 응답으로 바꿨습니다. 그래서 문제는 단순한 missing asset이 아니라 MIME type mismatch처럼 보였습니다.

JS asset 요청 실패가 index.html 200 응답으로 치환되면, 응답은 성공처럼 보이지만 Content-Type은 text/html이 됩니다. 실제 서비스 식별자는 마스킹했습니다.
CloudFront invalidation은 브라우저 runtime을 바꾸지 않는다
또 하나 헷갈렸던 지점은 invalidation입니다.
CloudFront invalidation은 CloudFront edge cache를 지웁니다. 사용자 브라우저나 웹뷰의 HTTP cache, 그리고 이미 메모리에 올라간 JavaScript runtime을 직접 지우지는 않습니다.
따라서 이미 열린 SPA는 invalidation 이후에도 자동으로 최신 index.html을 다시 받지 않습니다. 구버전 runtime이 계속 실행 중이라면 여전히 구버전 chunk 이름을 요청할 수 있습니다.
오히려 /* invalidation은 edge에 남아 있던 구버전 chunk까지 지울 수 있습니다. 이미 열린 구버전 SPA가 old chunk를 요청했을 때 edge cache hit로 버틸 가능성도 줄어듭니다.
그래서 invalidation은 /index.html, /처럼 HTML 진입점 중심으로 좁히는 것이 더 적절했습니다.
해결 전략
해결은 한 가지 설정으로 끝나지 않았습니다. HTML, asset, route, runtime 문제를 각각 분리해서 다뤘습니다.
index.html과 assets의 Cache-Control 분리
먼저 S3 object metadata를 분리했습니다.
index.html은 항상 최신 asset 목록을 담아야 하므로 재검증되도록 설정했습니다.
Cache-Control: no-cache, max-age=0, must-revalidate
Content-Type: text/html
반대로 hashed asset은 파일명이 바뀌면 URL도 바뀌므로 장기 cache가 가능했습니다.
Cache-Control: public, max-age=31536000, immutable
이렇게 하면 브라우저는 HTML 문서는 재검증하고, hash가 붙은 정적 asset은 길게 cache할 수 있습니다.
Custom Error Response 제거
다음으로 CloudFront Custom Error Response 기반 fallback을 제거했습니다.
Before:
/assets/js/missing.js -> /index.html 200
After:
/assets/js/missing.js -> 403 또는 404
이 변경으로 missing asset이 HTML 200으로 둔갑하지 않게 되었습니다. dynamic import 실패 자체가 완전히 사라지는 것은 아니지만, 적어도 실패가 정직하게 드러납니다.
CloudFront Function으로 route-only rewrite 적용
Custom Error Response를 제거하면 SPA deep link가 깨질 수 있습니다. /reports는 실제 S3 객체가 아니지만 SPA route로는 유효하기 때문입니다.
그래서 viewer request 단계에서 확장자 없는 route만 root index.html로 rewrite했습니다.
function handler(event) {
var request = event.request;
var uri = request.uri;
var lastSegment = uri.split('/').pop();
var hasExtension = lastSegment.indexOf('.') !== -1;
if (uri === '/' || !hasExtension) {
request.uri = '/index.html';
}
return request;
}
의도한 동작은 다음과 같습니다.
/ -> /index.html
/reports -> /index.html
/settings/profile -> /index.html
/assets/js/app.js -> 그대로 통과
/favicon.ico -> 그대로 통과
중요한 점은 route 요청만 index.html로 보내고, 확장자가 있는 정적 파일 요청은 그대로 통과시키는 것입니다.
또한 이 프로젝트의 Vite SPA dist 구조에서는 /reports/123을 /reports/123/index.html로 바꾸면 안 됐습니다. 실제 파일은 root의 /index.html 하나이기 때문에 항상 root index.html로 rewrite해야 했습니다.
CloudFront behavior 분리
CloudFront behavior도 역할별로 분리했습니다.
Default behavior는 HTML과 SPA route를 담당합니다.
Default behavior
-> HTML 및 SPA route 담당
-> CloudFront Function 연결
-> 짧은 TTL 또는 caching disabled 계열 정책
/assets/* ordered behavior는 정적 asset만 담당합니다.
/assets/* behavior
-> 정적 asset 담당
-> CloudFront Function 연결 없음
-> 장기 cache 정책
-> missing asset은 실제 403/404
asset 요청에는 route rewrite가 필요 없습니다. behavior를 분리해두면 나중에 Function 로직이 바뀌어도 asset 경로가 영향을 덜 받습니다.
배포 workflow에서 업로드와 invalidation 분리
workflow 수정 내용을 보기 전에, 이 글의 배포 환경을 짧게 설명하겠습니다. 우리가 운영하는 여러 프론트엔드 서비스는 정적 SPA 산출물을 만들고, 이를 S3에 업로드한 뒤 CloudFront를 통해 서빙합니다. 배포 과정은 대체로 다음 흐름을 반복합니다.
build
-> S3 upload
-> CloudFront OriginPath 갱신
-> CloudFront invalidation
이런 반복 작업은 서비스마다 매번 직접 작성하기보다 공통 GitHub Action이나 reusable workflow로 묶어두는 경우가 많습니다. 이 사례에서도 같은 방식으로 공통 배포 action을 사용하고 있었습니다. ci-cdn은 build와 S3 upload를 담당하고, cd-cdn은 CloudFront OriginPath 갱신과 invalidation을 담당했습니다. socar-actions는 이런 공통 action들이 모여 있는 내부 저장소입니다.
문제는 공통 action의 기본 S3 upload가 모든 파일을 한 번에 올리는 recursive upload 구조였다는 점입니다. 이 방식으로는 index.html과 assets/*에 서로 다른 Cache-Control을 주기 어렵습니다. 모든 파일을 한 번에 업로드하면 HTML과 hashed asset이 같은 metadata를 갖게 되기 때문입니다.
처음에는 공통 배포 action 자체를 수정하는 방법도 생각할 수 있습니다. 하지만 공통 action은 여러 서비스가 함께 사용하고 있었기 때문에, 특정 서비스의 캐시 정책을 위해 공통 동작을 바꾸면 다른 서비스에 영향을 줄 수 있었습니다. 그래서 공통 action은 최대한 유지하고, 해당 서비스 workflow에서 필요한 부분만 override하는 방향을 선택했습니다.
핵심은 build는 공통 action에 맡기되, 기본 S3 upload 단계만 끄는 것이었습니다. 이 공통 build action에는 빌드 결과물을 S3에 업로드할지 제어하는 옵션이 있었고, 이 글의 사례에서는 그 옵션이 build-upload였습니다. 이 값을 false로 내려 공통 action의 기본 recursive upload만 비활성화하고, 빌드 산출물은 workflow workspace에 그대로 남겨두었습니다. 이후 workflow에서 직접 S3 upload step을 추가해 assets/*와 index.html을 서로 다른 metadata로 업로드했습니다.
개념적으로는 다음과 같은 흐름입니다.
immutable"] E --> G["index.html 업로드
no-cache"] F --> H["cd-cdn OriginPath 갱신"] G --> H H --> I["기본 /* 무효화 off"] I --> J["/index.html, / 무효화"]
실제 workflow에서는 아래처럼 필요한 부분만 추가했습니다.
먼저 공통 ci-cdn action의 기본 업로드를 끄기 위해 환경변수로 BUILD_UPLOAD를 분리했습니다.
정밀한 내용은 보안상 생략합니다. 흐름만 봐주시면 됩니다.
# ci-cdn 공통 업로드(전체 no-cache recursive)를 끄고, Cache-Control 분리 업로드를 직접 수행한다.
BUILD_UPLOAD: 'false'
BUILD_OUTPUT: 'dist'
그리고 ci-cdn에는 이 값을 그대로 전달했습니다. 이렇게 하면 build는 그대로 수행하지만, 공통 action의 S3 recursive upload는 실행하지 않습니다.
- name: Run actions/ci
uses: ./.github/actions/ci-cdn
with:
build-upload: BUILD_UPLOAD
build-output: BUILD_OUTPUT
build-tag: BUILD_TAG
build-upload=false로 공통 upload를 끈 뒤에는 직접 S3 upload를 수행해야 하므로 AWS credentials를 별도 step에서 다시 설정했습니다.
# ci-cdn(build-upload=false) 대신 Cache-Control을 분리해 직접 업로드한다.
# 해시 에셋(/assets)은 영구 캐시(immutable), 엔트리(index.html 등)는 no-cache.
- name: Configure AWS Credentials for custom S3 upload
uses: aws-actions/configure-aws-credentials@v6.1.0
with:
aws-region: ap-northeast-2
role-to-assume: AWS_IAM_ROLE
실제 S3 upload step은 다음처럼 구현했습니다.
- name: Upload CDN files with Cache-Control
shell: bash
run: |
BUILD_TAG_VALUE="partner-center:dev-${GITHUB_SHA::6}"
test -f "${BUILD_OUTPUT}/index.html"
test -d "${BUILD_OUTPUT}/assets"
# 1) 해시 에셋: 1년 영구 캐시(immutable)
aws s3 cp --recursive "${BUILD_OUTPUT}/assets" "s3://${AWS_S3_BUCKET_NAME}/${BUILD_TAG_VALUE}/assets" \
--cache-control "public, max-age=31536000, immutable"
# 2) assets/index.html 제외 나머지: no-cache
aws s3 cp --recursive "${BUILD_OUTPUT}" "s3://${AWS_S3_BUCKET_NAME}/${BUILD_TAG_VALUE}" \
--exclude "assets/*" \
--exclude "index.html" \
--cache-control "no-cache, max-age=0, must-revalidate"
# 3) 엔트리 index.html: no-cache + text/html
aws s3 cp "${BUILD_OUTPUT}/index.html" "s3://${AWS_S3_BUCKET_NAME}/${BUILD_TAG_VALUE}/index.html" \
--cache-control "no-cache, max-age=0, must-revalidate" \
--content-type "text/html"
CD 단계에서는 공통 cd-cdn action의 OriginPath 갱신은 그대로 유지하고, 기본 /* invalidation만 껐습니다.
- name: Run actions/cd
uses: ./.github/actions/cd-cdn
with:
build-tag: BUILD_TAG
# OriginPath 갱신은 유지하되, 전체(/*) 무효화는 끄고 아래에서 엔트리만 직접 무효화한다.
aws-cloudfront-invalidate: 'false'
cd-cdn action에도 invalidation path 입력은 있었지만, 이 입력값을 사용하지 않고 별도 AWS CLI step을 두었습니다. 공통 action 내부에서는 path 값이 하나의 문자열로 전달되는 구조였고, /index.html과 /처럼 여러 path를 의도대로 분리해 전달하는지 확신하기 어려웠습니다. 그래서 공통 action에서는 OriginPath 갱신만 유지하고, invalidation은 별도 step에서 직접 실행해 대상 path를 명확히 지정했습니다.
그 다음 /index.html, /만 별도로 invalidation했습니다.
# /* 대신 엔트리(index.html, /)만 무효화 — 해시 에셋은 immutable이라 무효화 불필요.
- name: Configure AWS Credentials for custom CloudFront invalidation
uses: aws-actions/configure-aws-credentials@v6.1.0
with:
aws-region: ap-northeast-2
role-to-assume: AWS_IAM_ROLE
- name: Invalidate CloudFront HTML entry
shell: bash
run: |
aws cloudfront create-invalidation \
--distribution-id "${AWS_CLOUDFRONT_DISTRIBUTION_ID}" \
--paths /index.html /
여기서 주의할 점은 build-upload: false로 기본 upload를 끄면 공통 action 내부의 credentials 설정도 함께 실행되지 않을 수 있다는 점입니다. 그래서 custom upload 전에 AWS credentials를 workflow에서 명시적으로 설정했습니다. 이 부분을 암묵적인 action 내부 동작에 기대면, 나중에 공통 action 구현이 바뀌었을 때 배포 workflow가 깨질 수 있습니다.
CloudFront invalidation도 /* 대신 HTML 진입점 중심으로 좁혔습니다.
/index.html
/
이유는 invalidate해야 하는 대상과 cache에 남겨두고 싶은 대상이 다르기 때문입니다.
새 배포를 사용자에게 알리는 진입점은 index.html입니다. index.html에는 현재 배포가 참조해야 하는 최신 asset hash가 들어 있으므로, 배포 직후에는 이 문서가 빠르게 재검증되어야 합니다. 루트 경로 /도 결국 HTML 진입점으로 사용되기 때문에 함께 invalidate했습니다.
반대로 /assets/*는 hash가 붙은 불변 파일입니다. 파일 내용이 바뀌면 URL도 바뀌므로 새 배포를 반영하기 위해 기존 asset cache를 지울 필요가 없습니다. 오히려 /* invalidation으로 모든 경로를 지우면 edge에 남아 있던 구버전 hashed asset까지 같이 제거될 수 있습니다. 그러면 이미 열린 구버전 SPA가 old chunk를 요청했을 때 edge cache hit로 버틸 가능성이 줄어듭니다.
정리하면 invalidation의 목적은 "모든 파일을 새로 받게 하기"가 아니라 "HTML 진입점만 최신 여부를 확인하게 하기"였습니다.
invalidate 대상
-> /index.html
-> /
invalidate하지 않을 대상
-> /assets/*
-> 이미 hash로 버전이 구분되는 정적 파일
이렇게 해야 최신 HTML은 빠르게 반영하면서도, hash가 붙은 asset은 장기 cache 전략을 유지할 수 있습니다.
프론트 reload-once 방어
인프라 설정을 정리해도 남는 문제가 있습니다. 이미 열린 구버전 runtime이 old chunk를 요청했는데 그 chunk가 어디에도 없다면 dynamic import는 실패합니다.
이 케이스는 프론트에서 복구해야 합니다.
적용한 방향은 chunk load error를 감지했을 때 최신 index.html을 다시 받도록 한 번만 reload하는 것입니다.
구성은 다음과 같습니다.
vite:preloadErrorlistener- React Router root
ErrorBoundary - chunk load error 판별 helper
sessionStorage기반 동일 signature 1회 reload 제한- 재실패 시 자동 reload 대신 안내 UI와 수동 새로고침 버튼 제공
여기서 중요한 정책은 "무조건 reload하지 않는다"입니다.
API error, auth error, 일반 render error는 reload 대상이 아닙니다. chunk load error로 판단되고 실제 reload를 시도할 때만 event.preventDefault()를 호출했습니다. reload하지 않는 경우에는 Vite의 기본 throw를 유지해 ErrorBoundary fallback으로 전파되게 했습니다.
자동 reload가 실패하거나 이미 시도한 뒤 다시 같은 문제가 발생하면 안내 UI로 멈추도록 했습니다. 무한 reload보다 사용자가 수동으로 복구할 수 있는 상태가 더 안전하다고 판단했습니다.
preview nginx도 같은 정책으로 정렬
preview 환경은 S3와 CloudFront가 아니라 nginx 컨테이너가 dist를 직접 서빙했습니다. 따라서 CloudFront Function 대신 nginx location으로 같은 정책을 맞췄습니다.
핵심은 동일합니다.
/assets/*: 실제 파일만 서빙하고 없으면 404/index.html: no-cache- 확장자 있는 정적 파일: 실제 파일만 서빙하고 없으면 404
- SPA route:
index.htmlfallback
예시는 다음과 같습니다.
location ^~ /assets/ {
try_files $uri =404;
add_header Cache-Control "public, max-age=31536000, immutable" always;
}
location = /index.html {
try_files /index.html =404;
add_header Cache-Control "no-cache, max-age=0, must-revalidate" always;
}
location ~ \.[^/]+$ {
try_files $uri =404;
add_header Cache-Control "no-cache, max-age=0, must-revalidate" always;
}
location / {
try_files $uri $uri/ /index.html;
add_header Cache-Control "no-cache, max-age=0, must-revalidate" always;
}
적용 후 확인한 것
적용 후에는 다음 관점으로 확인했습니다.
/ -> 200 text/html
/index.html -> 200 text/html
/some-spa-route -> 200 text/html
/assets/js/index.hash.js -> 200 text/javascript
/assets/js/missing.js -> 403 또는 404
가장 중요한 확인 포인트는 missing asset이 더 이상 index.html 200으로 내려오지 않는다는 점이었습니다. 또한 SPA route 요청은 CloudFront Custom Error Response가 아니라 CloudFront Function rewrite 이후 일반 origin fetch 흐름을 타는지 확인했습니다. 이때 응답 헤더에서 X-Cache: Error from cloudfront가 아니라 X-Cache: Miss from cloudfront로 보이는 것을 확인할 수 있었습니다.
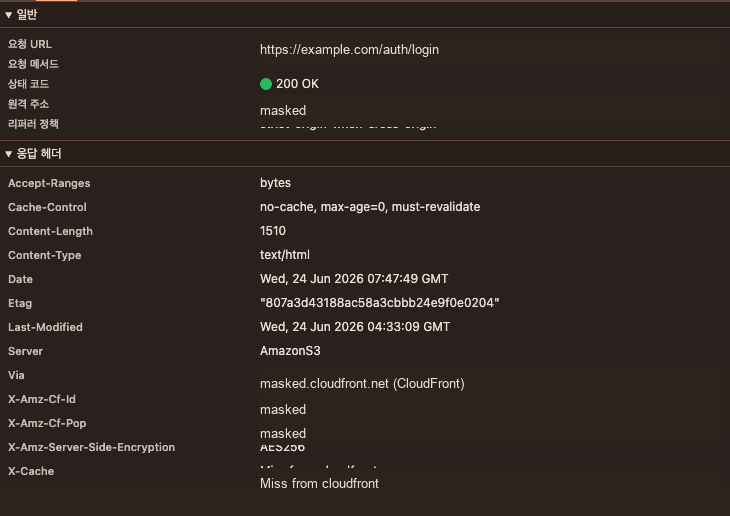
CloudFront Function으로 route-only rewrite를 적용한 뒤, SPA route가 Custom Error Response 경로가 아니라 일반 cache miss 경로로 처리되는지 확인했습니다. 실제 서비스 식별자는 마스킹했습니다.
요청 흐름도 다음처럼 바뀌었습니다.
asset 요청은 다음처럼 바뀌었습니다.
SPA route 요청은 별도 흐름으로 처리했습니다.
웹뷰별로도 관찰 차이가 있었습니다. Android WebView에서는 자동 reload 경로로 복구되는 케이스가 확인됐고, iOS WKWebView에서는 업데이트 안내 UI가 노출된 뒤 수동 새로고침으로 복구되는 케이스가 있었습니다.

이 차이를 실패로 보지는 않았습니다. Android는 자동 복구 경로를 탔고, iOS는 수동 복구 fallback으로 내려온 것입니다. 두 동작은 서로 다른 실패가 아니라 같은 방어 설계의 두 경로였습니다.
공통 표준으로 확장하기
이번 문제는 특정 프론트엔드 프레임워크의 문제가 아니었습니다. React, Vue, Svelte처럼 어떤 UI 프레임워크를 쓰는지보다 더 중요한 조건은 따로 있었습니다.
정적 SPA
-> HTML entry가 있음
-> hashed asset을 사용함
-> client-side routing을 사용함
-> CDN과 브라우저 cache를 거침
-> 새 배포 이후에도 열린 세션이 남아 있을 수 있음
이 조건을 만족하는 서비스라면 같은 유형의 문제가 반복될 수 있습니다. 그래서 후속 단계에서는 개별 서비스 대응을 넘어, 프레임워크에 구애받지 않는 SPA 배포 및 인프라 공통 표준으로 정리하는 것이 좋다고 봅니다.
공통 표준의 핵심은 앱 코드가 아니라 배포 계약입니다. 어떤 프레임워크를 쓰더라도 CDN 앞에 놓이는 정적 SPA라면 index.html, hashed assets, SPA route fallback, invalidation의 역할은 분리되어야 합니다.
배포 산출물 계약
가장 먼저 빌드 결과물의 의미를 명확히 해야 합니다.
dist/index.html
-> 최신 asset 목록을 참조하는 HTML entry
dist/assets/*
-> hash가 포함된 불변 asset
그 외 정적 파일
-> manifest, robots.txt, favicon 등
표준 규칙은 단순합니다.
index.html은 항상 재검증 가능한 entry로 본다.assets/*는 hash 기반 불변 파일로 본다.- SPA route fallback은 route 요청에만 적용한다.
- 확장자가 있는 누락 파일은
index.html로 fallback하지 않는다.
S3 객체 metadata 계약
S3에 올리는 파일도 같은 기준으로 나눕니다.
index.html
-> Cache-Control: no-cache, max-age=0, must-revalidate
-> Content-Type: text/html
assets/*
-> Cache-Control: public, max-age=31536000, immutable
기타 루트 정적 파일
-> Cache-Control: no-cache, max-age=0, must-revalidate
이 규칙은 특정 번들러에 묶이지 않습니다. Vite든 Webpack이든, 혹은 다른 도구든 최종 산출물이 HTML entry와 hashed asset으로 나뉜다면 같은 기준을 적용할 수 있습니다.
CDN fallback 계약
CloudFront에서는 fallback의 책임을 좁혀야 합니다.
SPA route 요청
-> /index.html rewrite 허용
asset 요청
-> 실제 파일만 응답
-> 없으면 403 또는 404
따라서 403/404 -> /index.html 200 형태의 전역 Custom Error Response는 SPA route와 asset 요청을 구분하지 못하므로 표준에서 제외하는 편이 좋습니다. 대신 viewer request 단계에서 확장자가 없는 route 요청만 /index.html로 rewrite하는 방식을 기본 규격으로 둘 수 있습니다.
function handler(event) {
var request = event.request;
var uri = request.uri;
var isAsset = uri.indexOf('/assets/') === 0;
var fileName = uri.split('/').pop();
var hasExtension = fileName.indexOf('.') !== -1;
if (!isAsset && !hasExtension) {
request.uri = '/index.html';
}
return request;
}
이 함수의 목적은 모든 에러를 숨기는 것이 아니라, SPA route만 HTML entry로 연결하는 것입니다.
invalidation 계약
CloudFront invalidation도 표준화 대상입니다.
권장
-> /index.html
-> /
비권장
-> /*
hashed asset은 파일명이 바뀌므로 이전 asset을 매번 무효화할 필요가 없습니다. 오히려 /* invalidation은 열려 있던 구버전 SPA runtime이 아직 참조할 수 있는 old asset까지 edge cache에서 지워, 배포 직후 실패 가능성을 키울 수 있습니다.
따라서 기본 정책은 HTML entry만 빠르게 갱신하고, hashed asset은 immutable cache에 맡기는 방식이 더 안정적입니다.
프론트 런타임 방어 계약
인프라와 배포 규격을 맞춰도 이미 브라우저나 웹뷰 메모리에 올라간 구버전 runtime은 즉시 바뀌지 않습니다. 그래서 프론트에는 최소한의 런타임 방어가 필요합니다.
다만 이 영역은 프레임워크와 라우터, 번들러 이벤트가 다를 수 있습니다. 따라서 공통 표준의 1차 대상은 특정 이벤트 이름이나 특정 라이브러리 API가 아니라 동작 원칙으로 두는 것이 좋습니다.
chunk load 실패 감지
-> 새 배포 가능성으로 간주
자동 복구
-> 1회 reload 시도
재실패
-> 무한 reload 방지
-> 사용자에게 업데이트 안내 fallback 제공
이번 사례는 Vite 기반이었기 때문에 vite:preloadError를 사용했습니다. Vite는 dynamic import 로딩에 실패했을 때 이 이벤트를 발생시키고, event.preventDefault()로 기본 throw를 막을 수 있습니다. 하지만 이 이벤트는 Vite 전용입니다. 공통 표준에서는 vite:preloadError 자체를 강제하기보다 “lazy chunk 로딩 실패를 감지한다”는 원칙만 정의하는 편이 맞습니다.
Webpack 환경에서는 Vite와 같은 전역 preloadError 이벤트가 아니라 dynamic import()의 Promise rejection이 기본 감지 지점입니다. Webpack의 dynamic import는 code splitting 지점이 되고, chunk 요청 실패는 보통 ChunkLoadError나 “Loading chunk failed” 형태로 나타납니다. 따라서 route lazy loader나 React.lazy wrapper에서 import().catch(...)로 감싸 reload-once 정책을 적용할 수 있습니다.
function lazyImportWithReload<T>(loader: () => Promise<T>): Promise<T> {
return loader().catch((error) => {
if (isChunkLoadError(error) && reloadOnceForChunkLoadError(error)) {
return new Promise<T>(() => {
// reload가 진행되므로 resolve/reject하지 않는다.
})
}
throw error
})
}
React Router에서는 lazy route loader, React에서는 React.lazy, Vue Router에서는 lazy route component, Angular Router에서는 loadComponent와 loadChildren이 각각 같은 계층의 감지 지점이 됩니다.
Vite
-> window vite:preloadError
-> event.payload 확인
-> reload-once 또는 fallback
Webpack
-> import().catch(...)
-> ChunkLoadError 계열 판별
-> reload-once 또는 fallback
React Router
-> lazy route loader / errorElement
-> ErrorBoundary fallback
Vue Router
-> component: () => import(...)
-> router.onError(...)
-> async route component resolve 실패 처리
Angular Router
-> loadComponent / loadChildren
-> withNavigationErrorHandler 또는 NavigationError
-> navigation error 처리
Vue Router는 route component에 dynamic import를 직접 사용할 수 있고, 라우터는 해당 route에 처음 진입할 때 component Promise를 resolve합니다. 이때 async component resolve 과정에서 잡히지 않은 에러는 router.onError(...)로 모을 수 있습니다. 따라서 Vue에서는 lazy route component를 그대로 유지하되, 전역 router error handler에서 chunk load error를 판별해 reload-once 또는 업데이트 안내 화면으로 연결하는 방식이 자연스럽습니다. route component가 아닌 일반 async component라면 defineAsyncComponent의 errorComponent, timeout 같은 옵션도 보조 fallback으로 사용할 수 있습니다.
router.onError((error) => {
if (isChunkLoadError(error) && reloadOnceForChunkLoadError(error)) {
return
}
// 업데이트 안내 fallback 또는 일반 에러 처리
})
Angular Router는 lazy route를 loadComponent나 loadChildren으로 정의하고, 이 loader는 Promise를 반환합니다. lazy chunk 로딩 실패는 navigation error로 이어질 수 있으므로 withNavigationErrorHandler(...) 또는 NavigationError 이벤트 구독 지점에서 chunk load error를 판별할 수 있습니다.
provideRouter(
routes,
withNavigationErrorHandler((event) => {
if (isChunkLoadError(event.error) && reloadOnceForChunkLoadError(event.error)) {
return
}
// 업데이트 안내 fallback 또는 일반 에러 처리
}),
)
결국 프론트 런타임 방어의 공통 규격은 다음 정도로 잡는 것이 적절합니다.
- 번들러 전용 이벤트는 adapter로 취급한다.
- route lazy loader 또는 dynamic import Promise rejection을 우선 감지 지점으로 둔다.
- 라우터 전역 에러 핸들러와 화면 단위 ErrorBoundary를 보조 감지 지점으로 둔다.
- chunk load error 판별과 reload-once 정책은 프레임워크와 무관한 순수 로직으로 둔다.
- 자동 복구가 실패하면 무한 reload 대신 업데이트 안내 fallback으로 내려간다.
검증 계약
마지막으로 표준은 문서로만 끝나면 안 됩니다. 배포 후 다음 응답을 확인할 수 있어야 합니다.
/index.html
-> 200 text/html
-> Cache-Control: no-cache
/assets/real-hash.js
-> 200 application/javascript
-> Cache-Control: public, max-age=31536000, immutable
/assets/missing.js
-> 403 또는 404
-> text/html 200이면 실패
/some-spa-route
-> 200 text/html
-> route-only rewrite 정상
CloudFront invalidation
-> /index.html /
-> /* 사용 금지
정리하면 공통화의 우선순위는 프론트 라이브러리보다 배포와 인프라 규격에 있어야 합니다. S3 metadata, CDN fallback, invalidation 범위는 프레임워크와 무관하고, 서비스별 UI 정책의 영향을 덜 받습니다. 반면 runtime error handling은 원칙을 먼저 표준화하고, 각 프레임워크와 번들러에 맞는 구현은 그 다음 단계에서 다루는 것이 자연스럽습니다.
마무리
이번 문제를 겪으며 SPA 정적 배포에서 중요한 것은 "파일을 CDN에 올리는 것"만이 아니라는 점을 다시 확인했습니다.
index.html은 최신 asset 목록을 알려주는 진입점이고, hashed asset은 오래 cache해도 되는 불변 파일입니다. SPA route fallback은 route 요청만 처리해야 하며, asset 요청까지 잡아먹으면 문제를 숨기고 디버깅을 어렵게 만듭니다.
CloudFront invalidation도 만능 해결책이 아닙니다. edge cache를 지울 수는 있지만, 이미 사용자 웹뷰에 올라간 SPA runtime을 바꾸지는 못합니다.
결국 안정적인 SPA 배포를 위해서는 계층을 나눠야 했습니다.
HTML
-> 빠르게 재검증
hashed assets
-> 길게 cache
SPA route
-> route-only rewrite
missing asset
-> HTML로 숨기지 않고 실패
runtime chunk load error
-> reload-once와 수동 fallback
S3와 CloudFront로 SPA를 배포한다면, index.html, hashed assets, fallback, invalidation을 각각 독립된 문제로 보고 설계하는 것이 중요합니다. 특히 WebView처럼 열린 세션이 오래 유지될 수 있는 환경에서는 인프라 설정과 프론트 런타임 방어를 함께 준비해야 합니다.
참고 자료
- AWS CloudFront - Generate custom error responses
- AWS CloudFront - Customize at the edge with CloudFront Functions
- AWS CloudFront - Invalidate files to remove content
- AWS CLI - cloudfront create-invalidation
- AWS S3 - Working with object metadata
- AWS CLI - s3 cp
- Vite - Building for Production: Load Error Handling
- webpack - Code Splitting: Dynamic Imports
- webpack - Module Methods: import()
- Vue Router - Lazy Loading Routes
- Vue Router - Router.onError API
- Vue - Async Components
- Angular - Route Loading Strategies
- Angular - withNavigationErrorHandler
- Angular - NavigationError
- React Router - Error Boundaries